
比年来,东谈主工智能冲突激勉了高性能GPU需求暴增。GPU坐褥商英伟达2023年市值增长239.2%,2024年又涨了45.9%,适度2月12日市值达到1.78万亿好意思元。GPU也曾成为公共高技术业界最炙手可热的商品之一,好意思国商务部还特等针对中国限制GPU性能,连游戏玩家用的RTX 4090都不让卖了。
在这种情况下,一些媒体防护到了中国的一项效果。2023年10月25日,清华大学戴琼海院士与乔飞副谈论员团队在《自然》杂志发表论文《All-analog photoelectronic chip for high-speed vision tasks》,先容了光电领略芯片ACCEL。一些新闻标题说这款芯片“算力是商用GPU的3000多倍”,内容中具体是“在包括 ImageNet 等智能视觉任求实测中,调换准确率下,比现存高性能 GPU 算力提高三千倍,能效提高四百万倍,具备超高算力、超低功耗的特色”。

这是确凿吗?这种光电领略芯片,能否在行业中应用延迟,匡助中国冲突GPU封闭?
其实这很猛进度是误读,因为这些媒体把ACCEL和商用GPU的“算力”拿来对比的门径有问题。简而言之,是把前者的遽然发达和后者的捏续发达同等看待了。但要深化贯穿问题在那里,咱们就要先来了解下光电领略芯片以及商用GPU芯片的基本学问,包括它们的架构与性能特色。
光电领略芯片ACCEL,顾名想义,它是一个芯片,但领略了“光”和“电”的性格。芯片有逻辑芯片和存储芯片两大类(还有一类半导体器件是功率放大器,偶然也称为功率芯片),高性能GPU即是将狡计才智开阔的逻辑芯片与多达几十G容量的先进存储芯片封装在一谈。
从性质上看,ACCEL是逻辑芯片,功能是狡计,况且狡计功能戒指为图像的方法识别。咫尺它还曲直常挑升的逻辑狡计芯片,莫得通用狡计功能。

天下第一款GPU:英伟达GeForce 256
GPU能不成作念通用狡计呢?以前不行,咫尺可以。GPU芯片起始功能专一,其前身叫“显卡”,处理的是2D屏幕上像素点的披露问题。1999年英伟达推出第一款GPU芯片GeForce 256时,矜重提议了GPU的定名Graphics Processing Unit,大概处理许多正本由CPU负责的T&L(Transforming & Lighting,几何光影颐养)算法,也曾有了通用处理器的一些性格。此时市集上CPU的价值如故更被敬重,用CPU来处理图像披露问题(如用CPU已毕的“软光栅”算法)奢靡了,就用GPU来打扶助,用其多核来并行处理天生顺应并行的图像披露问题。
英特尔其时以为,GPU是扶助的,没太大价值,于是干脆和自家的CPU集成在一谈卖,叫集成显卡。一般东谈主都不知谈我方的机器里有集成显卡,挑升买寂然显卡的东谈主才比较懂GPU。这可能是英特尔犯的最大荒唐,到2022年才运转推出寂然显卡,和英伟达、AMD抢买卖。
到2003年,GPGPU(General Purpose computing on GPU,GPU通用狡计)的观念被提议来。之后跟着GPU才智越来越强,到2010年之后,高性能GPU也曾能完成相称多不同种类的狡计任务,如图形3D、神经收罗、科学狡计、云狡计、数据中心、AIGC、假话语模子等等,相称通用了。到这个阶段,高性能GPU就显得比CPU有价值多了,价钱也拉开了几十倍的差距。可以这样说,CPU能狡计的GPU都能算,而GPU能快速完成的许多狡计任务,CPU表面上能完成但实在太慢,等于不行。是以咫尺的情况是,精练的任务才会让低廉的CPU干,CPU成打扶助的了。GPU霸主英伟达的市值,2024年2月12日达到了老牌CPU霸主英特尔的9.7倍,这即是GPU开阔狡计才智的平直体现。
底下咱们来看,光电领略芯片ACCEL是怎样作念狡计的。它领略了“光”与“电”,其中“光”是指“光狡计”(photonic computing),“电”即是电子。跟电子比较,光子有很凸起的性能,举例莫得静止质地,光子之间莫得彼此作用劲,彼此险些不搅扰,不受电磁场搅扰等等。在通讯业中,光纤就比铜缆的带宽大得多,能耗还小,光通讯是进修应用了。电子的优点是,天生顺应二进制逻辑狡计,因为有半导体的神奇功能,通过电压变化,器件就能在导通和阻断之间贤达变化,恰巧代表了0和1。

《三体》电视剧中的东谈主列狡计机
稍有狡计机学问的东谈主,会明白基于电流、电压的半导体作念狡计是比较自然的,二进制逻辑不难解。就如刘慈欣《三体》中形容的,用几个士兵就能演示与、或、非基本逻辑狡计,进良友毕加减乘除等数学运算,直到整个这个词狡计机系统。
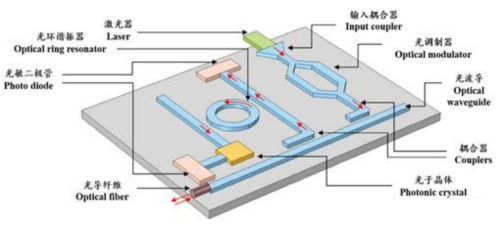
集成光路示意图
光子其实亦然可以搞狡计的,况且是零能耗。上图是一个与“集成电路”类似的“集成光路”,激光器产生的光在“光路”的万般元器件里传输处理,效果很是于狡计。你可能会意料我的一又友袁岚峰平淡先容的、中国科学本领大学研发的“九章”系列量子狡计机,但它和这里说的光狡计并不是一趟事。九章亦然用光来作念狡计,但它是哄骗单个光子的量子性格,如肖似和纠缠。而一般说的光狡计,用的如故无数光子的插手、衍射等经典性格。
举例一束光通过透镜衍射,就可以贯穿为实行傅里叶变换积分。整个这个词过程是“无源”的,能耗为零,无须如集成电路那样外加电源。再一个例子是马赫-曾德尔插手仪(MZI,Mach–Zehnder Interferometer),可以平直构造出一个2 × 2的矩阵,亦然无源的。级联的MZI可以进行矩阵乘法,相称有性格,让MZI成为光狡计的基础单元,ACCEL论文里也提到了MZI。这就有些专科了,不象电子天下的二进制逻辑那样容易贯穿。
底下咱们来稍许崇拜地先容一下马赫-曾德尔插手仪。你可能传说过恩斯特·马赫,他曲直常着名的物理学家和形而上学家,爱因斯坦屡次闪现受到过他的很大启发。但马赫-曾德尔插手仪中的马赫并不是恩斯特·马赫,而是他的男儿路德维希·马赫。路德维·曾德尔1891年提议这种插手仪的构想,路德维希·马赫1892年改进,两东谈主提议的这种插手仪构型很机动,被粗鲁应用于量子力学的基础谈论。MZI自后应用到了光通讯,近来又用到了光狡计,在光学测量中也很常用。
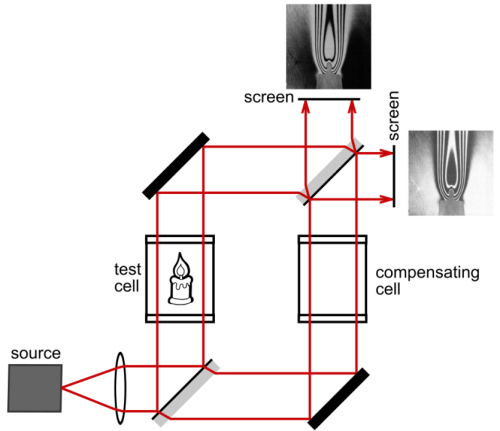
马赫-曾德尔插手仪示意图
如图,马赫-曾德尔插手仪的图像效果是,检测盒(test cell)中的火焰物体,在右方披露为白色火焰(相长插手,Constructive Interference),上方披露为玄色火焰(相消插手,Destructive Interference)。中枢安装是左下和右上两个“半镀镜”,镀膜的厚度很小,恰巧让45度角入射的一半晴明透射往日,一半反射走。光源经过透镜造成准直光束,被左下的半镀镜分红两谈,往上走的叫“样品光束”,平走的叫“参考光束”,半镀镜等于起到了“分光器”(beamsplitter,BS)的作用。参考光束的光路上有一个赔偿盒(compensating cell),是和磨真金不怕火盒(test cell)一样的玻璃盒,摈斥两条光路除样品外的颠倒影响。全心颐养,让两条光路距离一样。两个光束分辨被左上和右下的镀银镜全反射,又在上方的半镀镜遇上,一半样品光束透射过它,和被它反射的一半参考光束一谈到达右边探伤器(屏幕),发生相长插手;一半样品光束被它反射,和透射过它的一半参考光束一谈到达上头的探伤器,发生相消插手。
你可能想问,既然两条光路距离调换,为什么不是双方都是相长插手,而是一边相长,一边相消?重要道理是,反射有可能改造相位,也可能不变。最终两束光相位违犯即是相消插手,相位调换即是相长插手。仔细不雅察,左下的半镀镜是镀膜(细黑条)在上、玻璃(粗灰条)不才;右上的半镀镜是玻璃在上、镀膜不才。
反射相位改造与否的法规是由菲涅尔方程决定的:在低折射率介质里传的波动,投入高折射率的介质,波动相位会变。也即是从低到高反射,相位会变,但从高到低反射,相位不变。样品光束在左下半镀镜反射走,是从空气到镀膜,空气折射率低于镀膜,会改造一次相位(参考光束被右上半镀镜反射类似)。而样品光束在右上半镀镜反射走,是从玻璃到镀膜,玻璃折射率高于镀膜,不改造相位。
透射是不改造相位的。咱们看样品光束和参考光束经过的反射,就会发现,在右边屏幕发生插手时,两束光的相位改造次数是一样的(全反射镜也算一次,各改造了两次),相位调换,相长插手。而在上边屏幕发生插手时,样品光束的相位改造多一次(样品光束两次,参考光束一次),两者反相了,相消插手。
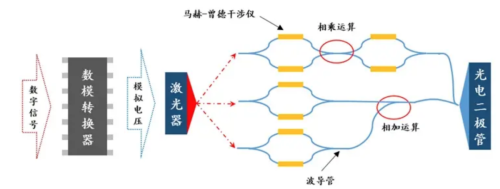
那MZI是怎样用到光狡计内部的?马赫与曾德尔是提议实验构想,具体的插手已毕多种万般,只淌若光束经过分光器,经不同旅途又发生插手,就顺应粗野,通称为MZI。光的加法很精练,即是两束光通过波导管传输,在波导管相遇的方位,信号被标的耦合器加在一谈。而光的乘法即是MZI的插手效应已毕的,自然器件比原始的马赫-曾德尔插手仪要小得多了,有好多改进。
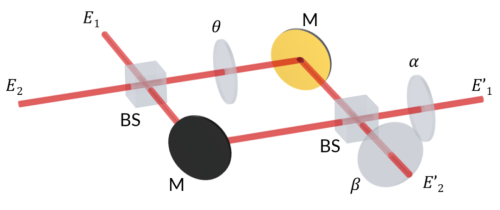
单个经典的MZI:两个分光器BS,两个反射镜M,三个移相器
如图,一个经典的MZI和原始的马赫-曾德尔插手仪梗概类似,两个分光器就等于半镀镜,两个反射镜也一样。但是,多了三个移相器,入射的光也变成两个了,E1和E2两束光都是一半透射一半90度角反射,透射的和另一束光反射的恰巧同标的。E1和E2就代表一个2 × 1的矩阵E = [E1, E2],这个矩阵经过MZI乘以2 × 2的矩阵U,就变成另一个2 × 1的矩阵E’ = [E’1,E’2],公式是E’ = E * U。移相器的三个角度值α/β/θ,代表相乘的2 × 2的矩阵U,U的数值是可变的(也即是可编程的),但必须是酉矩阵(unitary matrix,也叫幺正矩阵),是以矩阵的4个值用3个参数可代表。酉矩阵的界说是,它和另外一个矩阵乘,能得出对角线全是1的单元矩阵,具有一定的对称性。具体的数学公式很复杂,但梗概道理并不难明白。晴明在MZI里凭证相位插手,两条光路很是于两个并行的数值狡计。这个MZI就代表了2 × 2的矩阵U。
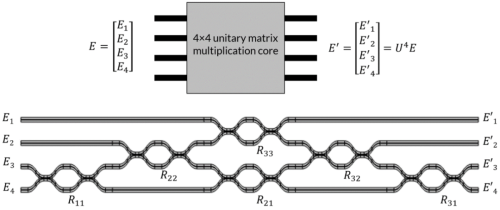
这个架构是可扩展的,举例将4×1的输入矩阵E剖析,用6个MZI,就能获取E与4×4的矩阵U相乘的罢了E’。法规是,n×n的酉矩阵U,可以用n(n-1)/2个MZI来闪现。上图U的上角标4代表它的维度是4。
哄骗矩阵的奇异值剖析法(Singular Value Decomposition, SVD),级联MZI可以已毕即兴矩阵的乘法。SVD是说,即兴m × n的矩阵M,可以闪现为三个矩阵的乘积,M = UEV,其中U是n × n的酉矩阵,V是m × m的酉矩阵,E是m × n的对角矩阵(对角线除外全是0)。这三个矩阵都可以用级联MZI来闪现,对角矩阵更精练,用n个MZI光衰减器就可以。防护一般的n × n方阵也需要用SVD剖析,因为可能不是酉矩阵。
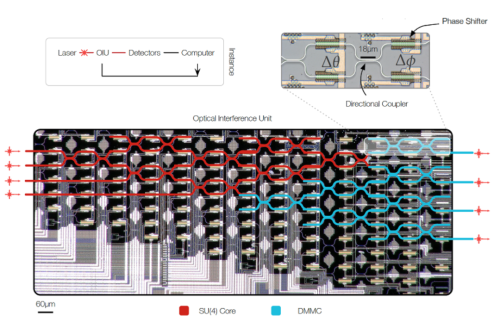
图为级联MZI组成的光学插手单元(Optical Interference Unit,OIU)。这些遐想也曾有骨子的光子芯片应用了。MZI观念上是光子芯片的元器件,偶然需要相称多的数目,如64 × 64的矩阵乘法就需要8128个MZI。
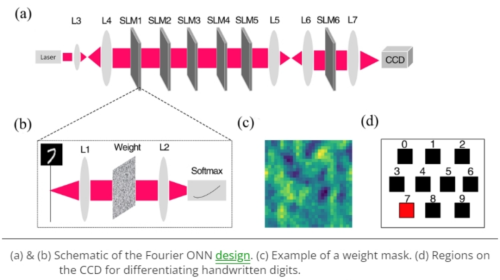
近来相称流行的神经收罗深度学习,最常用的基础运算是卷积。而透镜衍射的傅立叶变换就可以模拟卷积运算,因此用光学元器件模拟深度神经收罗是可行的,这即是光学神经收罗(Optical Neural Network, ONN)。图为一个手写数字识别ONN,一个空间光调制器(SLM,Spatial Light Modulator)就很是于深度神经收罗中的一层。有一个实体的掩码板(weight mask),等于是权重整个,放在光路中当作整个调制卷积过程。L7作逆的傅立叶变换,把晴明聚焦到CCD中的某个区域。运行起来效果是,输入端晴明代表的数字,经过透镜与掩码组,终末总能神奇地聚焦到CCD的对应区域。这个过程的数学解说,即是深度神经收罗。
光狡计有顽劣耗的性格,但是因为狡计机系统没法解读光信号,骨子应用时还需要光电颐养以及最终输出处理枢纽。
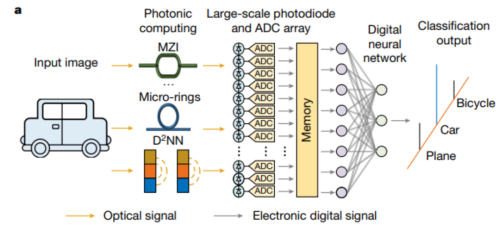
传统的光狡计应用过程,摘自ACCEL论文
图为传统的图像识别光狡计应用过程,小车的图像是光信号输入,经过MZI光狡计、D2NN(即是一种ONN,衍射深度神经收罗)处理,造成了特征彰着的光信号。但这些光信号要经过好多photodiode(光电二极管)转成电信号(基于光电效应),再从电信号经ADC(模数颐养)变成数字信号投入狡计机内存,还要跑一个袖珍数字神经收罗全聚首层(在光信号那里作念不轻便),最终造成识别罢了,认出是小汽车。
这个传统光狡计应用架构短处很大。说是光子零能耗,但是大鸿沟的光电颐养、ADC颐养相称耗能。晴明在繁密级联MZI、透镜掩码组里传播、插手、衍射,这个过程并不是很靠谱,也即是“非线性”,元器件一多就不灵了。况且也不抗搅扰,晴明稍有点环境扰动罢了就不合。比较之下,基于电子的芯片就很靠谱,信号在上百亿个晶体管之间传送都不会错。是以传统的光狡计多年来都只可“展示后劲”,如果是眷注前沿本领进展的一又友,和会常在著作中看到它,但从来不见它大鸿沟应用。这即是因为它应用不轻便,从光信号到数字信号过程生硬,光电领略得不好。
了解了这些配景,才能明白清华团队ACCEL的跨越。它奥妙地领略了光子与电子各自的性格上风,是以叫光电领略芯片。ACCEL的全称是All-analog Chip Combining Electronic and Light computing,全模拟电光狡计领略芯片,这里的重心除了光电领略,即是All-analog,全程模拟信号,省去了耗能的ADC枢纽。
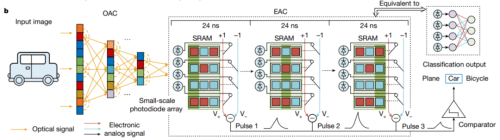
ACCEL的架构
ACCEL的图像识别过程,分为OAC(Optical Analog Computing,光模拟狡计)和EAC(Electronic Analog Computing,电模拟狡计)两个枢纽。小车的光学图像包含极多光学信号,经过光学元器件阵列,陆续进行“特征索取”,很是于用ONN已毕深度神经收罗运算,在OAC里生成了小量光学信号(但包含了重要信息)。OAC输出的光信号,经过少许光电二极管阵列颐养(唯独32 × 32个),变成电信号(仍然是模拟信号)。这些电信号在EAC里的SRAM阵列里传输,用奥妙的办法模拟了一个神经收罗全聚首层。终末电信号造成了精练的脉冲序列输出,完成识别过程。
可以看出,OAC鉴戒了ONN的本领,主要的转换是在EAC枢纽。SRAM是static random-access memory,存储一个比特。EAC模拟已毕了一个二值化的神经收罗全聚首层。全聚首是方法识别的深度神经收罗终末一层常用办法,EAC里是1024 × N的全聚首(1024即是32 × 32个从OAC颐养来的电信号,N是需要识别的物体种类数,ACCEL里N小于等于16)。
二值化神经收罗聚首是说,权重整个唯独两种景象(正和负)。每个从光信号转来的电信号,会凭证其聚首的SRAM存储的比特值是0如故1,决定连到V+如故V-这两条线之一。两条线各有一些电信号连过来,先各自凭证基尔霍夫定律合并出电流值,再在输出Node彼此比较电流大小,得出一个电压差脉冲输出。如果有N个物体需要分辨,从OAC颐养来的电信号会同期接到N组SRAM里,组合出N个脉冲输出。终末脉冲在Comparator里比较,哪个大就代表识别罢了是它。神经收罗老师,即是凭证正确输出罢了,告诉EAC,对应Node输出的脉冲大了、小了,反向去修改SRAM里的0和1值。老师好了,1024×N个SRAM里就存储了一套权重整个,可以用于方法识别了。
整个这个词过程很奥妙,EAC的输出平直就识别好了,不需要再在传统狡计机里狡计处理。是以,ACCEL芯片已毕了完整的图像识别狡计过程。它内部有光学信号、电信号,在一级级传输,有个狡计过程,但竣工莫得传统芯片的数字逻辑过程。是以叫作念All-analog,全程模拟信号,不需要ADC颐养,这就相称强横了,能效极高。
ACCEL的优点有多种。在OAC枢纽,光学图像输入包含海量的细节,用透镜和掩码组陆续变换,终末就造成32×32的小鸿沟输出。这个特征索取过程相称清贫,它是光电领略芯片能快速狡计的主要元勋,是一个光学过程,光速、低时延、顽劣耗。这个过程如果用传统芯片来作念,需要相称多的晶体管,况且并行拦阻易,需要GPU加快。光学过程自然即是并行的,况且已毕精练。
但OAC的输出是“详细”的,谁也看不懂。如果导入传统狡计机系统里解读,就又引入了传统内存与逻辑芯片的毛病,还不如只用传统芯片处理精练。ACCEL用EAC去解读OAC的输出,用SRAM阵列很精练地就进行了电流狡计,最终的电流脉冲罢了能和识别罢了很好地对应上,这是一个让东谈主叫绝的办法。
架构遐想可以,还要评估骨子效果。清华谈论团队对MNIST、ImageNet数据集的几个典型学术谈论型案例,评估了运行效果。这些案例包括,10个手写数字的识别、3类图形样例的识别,还有一个视频行为的分类识别。
要防护,ACCEL芯片架构评估其实不需要骨子造出芯片,可以先模拟评估。就如同芯片遐想时,可以选择器用软件模拟运行看效果,看遐想是否奏效。ACCEL的OAC和EAC的信号处理行为,都可以用狡计机模拟出来。模拟运行、老师神经收罗,考据架构可行性、方法识别效果让东谈主散漫,再去骨子造出ACCEL。
这种模拟就能发现传统光狡计芯片的毛病了。如ImageNet中256×256的图像分类识别,对传统光狡计架构很困难,因为要放好多MZI,需要的ONN层数较多,会导致光信号在光路上经过的枢纽过多,非线性性格发作,性能乱套。ACCEL对这类较大的图像还能草率过来,讲明架构上比传统光狡计要强好多。
但是需要指出,ACCEL模拟评估的门径,就讲明它仍然是一个谈论型的芯片。这些评估的任务是相对精练的,如对ImageNet中的三类物体进行分辩,栗色马、救护车、衣柜。ACCEL的识别率是80.7%,这听起来不高,但仍然高于它的比较对象、一个传统数字神经收罗的75.3%。为什么呢?因为这个比较对象仅仅一个三层的精练收罗。昭彰这意味着双方离委果应用都很远。咫尺委果实用的深度学习方法识别的识别率很高,大概处理的图片较大,应用的神经收罗层数相称多,跟这种“玩物模子”不是合并层面的。
之后,清华团队骨子造出了ACCEL芯片,进行了评估。但由于其谈论型目的,用的工艺是相对精练的。传统光狡计芯片的问题是,在制造过程中,会出现光路对皆、信号噪声之类的残障,大大影响骨子发达。ACCEL由于芯片架构精练,是以在这方面发达好一些,制造引入的残障少,信号噪声、低光照条款下发达可以,亦然一个优点。ACCEL就算造的不圆善,因为权重是凭证骨子样例老师的,能在老师中更正一些。
ACCEL制造出来后,在一些测试样例中,识别率发达和模拟评估一致,有的数值稍差一丝但可以贯穿。到这一步,才讲明芯片遐想和制造算是奏效的,已毕了意图,之后关于优厚性能的讲明才有道理。
总体来说,ACCEL识别率方面的性能磋磨还可以。一个特等大的优点是,在低照度的情况下,传统办法全部会失败,但ACCEL还能很好地处理。这是因为其它架构都需要ADC模数颐养,信号强度不够就不行了。而ACCEL在低照度情况下,模拟信号仍然能正常地自然运算,直到整个这个词狡计完成。
咫尺咱们回到著作起首的问题,新闻里说的“算力是商用GPU的3000多倍”,这话究竟对不合呢?其实竣工误导,它只可贯穿为一种形色,并不是骨子的算力发达。
起始来贯穿一下,这个说法是怎样来的。ACCEL的优点是,它即是一个光信号、电信号传播的过程,不象传统芯片那样狡计速率受限于“时钟周期”。可以想象,传统芯片的狡计过程是一步步的,象僵直的机器东谈主一样一个节奏动一下。而ACCEL是一个活水一样的自然过程,险些莫得卡顿,自然偶然钟周期,但不太受限制,唯独SRAM存储更新之类的彰着需要节奏的方位会用到。
实测下来,ACCEL用2-9个纳秒就能完成一幅图像的处理。1纳秒是十亿分之一秒,是100万之一毫秒。平淡东谈主们用CPU处理一幅图像识别是几十到几百毫秒,用GPU加快也要几个毫秒。也即是说,ACCEL的处理时候唯唯一般芯片的百万分之一以下。
因此,可以以为ACCEL的时钟频率是500M,也即是一个时钟周期2纳秒。等于是说,几个时钟周期,ACCEL就把狡计任务办完毕。而在传统狡计机里,不管是CPU如故GPU,这类狡计任务都要好多个时钟周期的,作念个乘法就要好多步。并行是说,海量数据可以组成向量加快,但对某个数据处理的时钟周期是省不了的。
是以清华论文陈述说,在进行ImageNet三类物体分类时,ACCEL的狡计速率约很是于4550个TOPS。TOPS是Tera Operations Per Second,代表每秒1万亿次操作。这个狡计速率确乎能有商用GPU的3000多倍,因为GPU每秒能有1万亿次操作也曾很好了。所谓“算力是商用GPU的3000多倍”,即是这样来的。但这个说法,究竟是那里不合呢?
委果的问题,在于捏续狡计。ACCEL确乎能在几纳秒之内处理一幅图像的光信号,但它能不成捏续运算,确凿用一秒时候,完成4550TOPS的运算量?这就不行了,因为准备任务是需要时候的。举例以它的狡计速率,一秒能处理1亿个图片,但把这样多图片的光信号在一秒内发送给它,是不可能的。骨子准备一个图片需要的时候就不短,委果的瓶颈是在这儿。
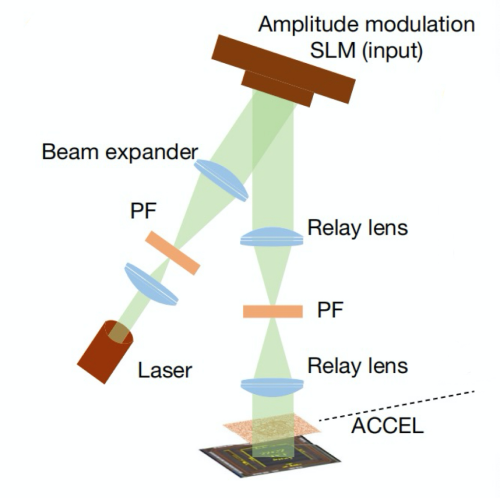
ACCEL芯片测试准备
ACCEL芯片是一个光电芯片,它的输入是光信号,要把它运行起来,需要准备好光信号输入,而这是个很是复杂的任务。按论文形容,清华团队要搭起光学镜片组,才能将识别主义的光信号输入给ACCEL进行处理,换下一个识别主义要不少操作。而GPU、CPU在狡计机系统中应用多年了,处理输入也曾很进修了,是以能将海量数据组织起来,象活水线一样送到运算中枢不休处理。高性能GPU的中枢本领之一,即是海量数据输入管制,要用到上百G的高速存储器,多级缓存。
是以,论总的算力ACCEL并不大,它仅仅对整个这个词经由中的一步处理得极快,而这一步快的代价是另一些法子慢。一个譬如是,一个士兵眼前恰巧有一个敌东谈主,他开枪只用1秒钟就散失了一个敌东谈主。但这不代表他可以一小时散失3600个敌东谈主,更不是说他可以一个东谈主顶3000多个东谈主。如果有东谈主说他的“战力”有3000多个士兵这样多,这就错得离谱。再一个譬如是,一张弓,可以在1秒内让箭飞出100米,速率很快。但是,不成说它的“运载才智”是1小时360公里,因为没法捏续飞。如果射一箭,东谈主走往日再射一箭,这样勤快,一小时跑不了多远。
如果是了解可控核聚变的一又友,可能会意料另一个更有本领含量的譬如。可控核聚变有两条路线,磁拘谨和惯性拘谨。咱们平时平淡看到新闻的EAST、ITER等托卡马克属于磁拘谨,而激光打靶属于惯性拘谨。2022年12月,好意思国国度燃烧安装(NIF)已毕了一个里程碑,能量输出高出了输入。但是,这意味着惯性拘谨聚变能用来发电了吗?其实还差得远。原因有好多,其中之一即是激光打靶是不一语气的,聚变反映时候唯独几纳秒,而准备一次打靶却要一天(好意思国NIF激光聚变“燃烧”奏效,聚变电站还远吗?|DrSHI不雅科技)。这比“一曝十寒”还夸张,是“纳秒曝一天寒”,是以总的效力相称低,离实用还很远。
而比较之下,GPU的算力即是真实的,它确乎能一语气一直跑,跑到芯片发烫,东谈主东谈主都能听见电扇的声息。GPU应用时,会有配套的狡计机系统、应用圭臬、CUDA驱动赈济,偶然需要上百G的HBM3快速存储,这都是为了一语气处理海量数据。
另一个磋磨是与能耗联系的。ACCEL险些毋庸能量,唯独激光、SRAM用一丝,能耗磋磨相称优秀。论文中给出的能耗磋磨是74800TOPS每瓦,这即是新闻中提到的“能效提高四百万倍”。
不异的兴味,这种说法亦然很误导的。这是因为ACCEL处理整个这个词经由中的一步险些毋庸能量,而不是ACCEL真用了与CPU或GPU很是的能量,完成了四百多万倍的运算。一个譬如是,一只蚂蚁险些毋庸能量就能爬1米,能耗效力比东谈主要高多了。但是东谈主可以把10斤重的箱子拿起来,蚂蚁却不可能作念到。
终末,咱们往返来一下。清华ACCEL芯片领略了光电的性格,曲直常奥妙的芯片架构,本领磋磨优秀,将光狡计的后劲进一步展示。是以这个责任发表在《自然》上,激勉了很是的震憾。它的快速狡计、低功耗的性格,正如论文中提到的,在可衣着缔造、自动驾驶、工业检测等领域很有应用远景。应该说清华团队的回来是澄澈的,在这些领域视频图像信号能低功耗快速处理,会是可以的应用。
但是,一些媒体将磋磨践诺到与GPU对比,以为ACCEL的算力与功耗磋磨比GPU好得多,致使默示ACCEL可能处罚先进GPU问题,这就竣工误读了。一方面的问题是,GPU有“通用狡计”才智,能完成好多复杂任务,而ACCEL只用于视频与图像方法识别,应用领域较窄。但根底的问题是,磋磨对比门径荒唐。这种比法对ACCEL来说是只看到上风,没看到代价,对GPU来说是暴虐了GPU一语气狡计的才智。
更深脉络的问题是,媒体为什么平淡犯这种荒唐呢?或许是因为他们总想搞个大新闻,而忽略了提高学问水平。
下一篇:走失的保障代理东说念主
- 12月24日基金净值:博时主题LOF最新净值1.017,涨1.4%2024-12-25
- 12月24日基金净值:南边中证新动力ETF最新净值2.0486,涨1.68%2024-12-25
- 12月24日基金净值:招商中证红利ETF最新净值1.5482,涨1.14%2024-12-25
- 12月24日基金净值:博时央企结构调养ETF最新净值1.3399,涨1.05%2024-12-25
- 胡塞反以大旗:以军胁制失败,纳降绝无可能2024-12-25
- 5%照旧3.5%?特朗普“援乌”交游,欧洲被动卷入武备竞赛!2024-12-25